


Een boek over Singularity kan niet zonder een hoofdstuk over Big Data, want dit is een belangrijke drijfveer achter de acceleratie van technologische en wetenschappelijke ontwikkelingen. Retailers weten heel goed dat we op bepaalde momenten in ons leven gevoeliger zijn voor prikkels die onze routines kunnen veranderen. Het van tevoren weten wanneer zulke momenten plaatsvinden, is waardevol voor bedrijven omdat dit hen kan sen biedt om deze routines in hun voordeel te veranderen.
Als een luierfabrikant van tevoren weet wanneer een jong stel hun eerste kindje verwacht, creëert dit de mogelijkheid om hun producten te ‘pre-promoten’ met een vrijwel perfecte timing. En luierfabrikanten weten dat, als we eenmaal ‘gewend’ zijn geraakt aan een specifiek merk, de kans op herhalingsaankopen (retentie) op een zeer hoog niveau blijft met vrijwel nul kosten. Daarom heeft informatie met betrekking tot die speciale momenten economische waarde.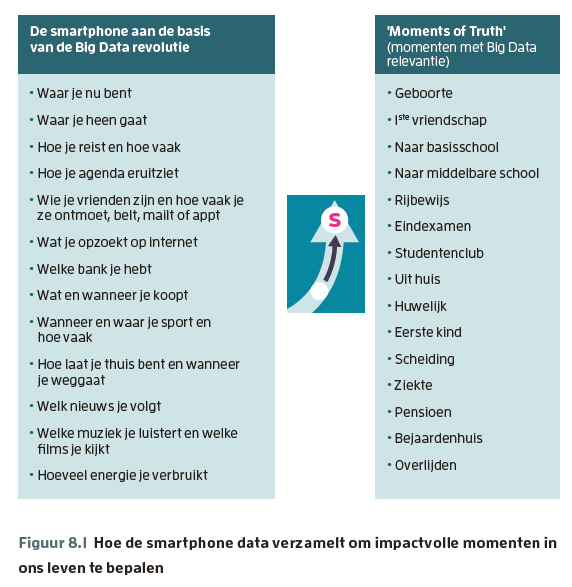
Smartphones primaire databron
Onze smartphones zijn de primaire en continue bron voor het verzamelen van data. Onze smartphone verzamelt continu gegevens alleen al doordat we het apparaat gewoon bij ons dragen. Niet alleen die van jou en mij, maar de gegevens van alle 2,5 miljard smartphonegebruikers op deze planeet worden verzameld en opgeslagen. En door dit te doen, worden deze gegevens Big Data. Vooral wanneer verschillende databases van verschillende bronnen zijn gekoppeld (bijvoorbeeld een combinatie van de gegevens van een telecomprovider met de gegevens van de zoekmachine van Google en de AH-klantenkaart) ontstaat zeer waardevolle informatie. De gegevens van één persoon zijn zeer interessant (bijvoorbeeld wanneer deze gegevens bedrijven kunnen leiden naar die zogenaamde ‘momenten van de waarheid’), maar de gegevens van velen zijn nog veel waardevoller. Zulke enorme databases (samen met krachtige computers) geven ons de mogelijkheid om te zoeken naar ‘statistische verbanden’. En als we de statistisch betrouwbare correlaties ‘bezitten’, kunnen we beginnen met het voorspellen van het individuele gedrag. Mensen leven met veel routines. En hoewel we allemaal denken dat we anders en speciaal zijn, zijn we in ons gedrag heel vaak hetzelfde! Dagelijkse routines kunnen veranderen in de loop van de tijd, maar zelfs deze veranderingen komen vaak overeen met statistisch betrouwbare patronen. Dus, als we erin slagen om toegang te krijgen tot grote hoeveelheden historische gegevens en waar mogelijk toekomstige trendmatige gegevens ophalen, kunnen we betrouwbare modellen bouwen om toekomstig gedrag te voorspellen.Big data en griep
We kunnen – gebaseerd op smartphonegegevens – betrouwbare uitspraken doen over de griep, de ontwikkeling van de epidemie per regio en mogelijke verdere verspreiding. Omdat jij, net als een aantal andere personen in jouw straat en buurt, nog steeds thuis bent op dinsdag na 10.00 uur (terwijl je normaal je huis om 08.00 uur verlaat), je die ochtend alle vergaderingen voor die dag in je elektronische agenda annuleerde én je via Google zocht naar ‘hoofdpijn’. Google is al in staat om nauwkeurig en tijdig te voorspellen hoe de griep zich verspreidt per regio op basis van enkele zoekwoorden die significant vaker worden gebruikt door mensen in de aanloop naar de echte ziekteverschijnselen! Deze bijzondere ‘zoekwoorden’ worden gevonden door het simpelweg analyseren van de miljarden hits die Google dagelijks verzamelt, in combinatie met de historische databases over de griep van de Centers for Disease Control. Op basis van deze uitkomsten ontdekten ze dat een aantal zoekwoorden significant vaker wordt gebruikt in de dagen vóórdat we ons eigenlijk ziek voelen, ons ziek melden of een bezoek aan een arts brengen. Zo begon Google met het opbouwen van voorspellingsmodellen en de Centers of Disease Control maken nu daadwerkelijk gebruik van Google’s modellen in plaats van hun eigen modellen. Figuur 8.2 geeft inzicht in drie fundamentele veranderingen die momenteel plaatsvinden in de Big Data revolutie (klik voor groter).
Figuur 8.2 geeft inzicht in drie fundamentele veranderingen die momenteel plaatsvinden in de Big Data revolutie (klik voor groter).








